
Os modelos de machine learning ![]() têm um papel crucial nas indústrias, possibilitando a criação de ferramentas que aprimoram o dia a dia das operações. No contexto da logística de produtos, surge a necessidade de resolver um problema específico.
têm um papel crucial nas indústrias, possibilitando a criação de ferramentas que aprimoram o dia a dia das operações. No contexto da logística de produtos, surge a necessidade de resolver um problema específico.
Pensando em um projeto prático e que fosse ideal para empresas que necessitam entender o comportamento de saída de seus clientes de suas empresas, desenvolvi um modelo preditivo de machine learning para prever o churn de clientes da empresa “GadgetDotCom”, utilizando o algoritmo RandomForest.
Assim, dividi o projeto em 07 fases, que apresento abaixo:
1 – Concepção do problema
A GadgetDotCom, empresa líder em eletrônicos e streaming, enfrentou um desafio inesperado: o estagnamento de sua base de clientes. Uma análise detalhada revelou que a taxa de churn havia aumentado em 15% nos últimos seis meses. Essa situação, que contradizia as projeções de crescimento, gerou grande preocupação na alta direção.
Após uma análise aprofundada, a equipe de negócios identificou que a falta de personalização dos serviços e a concorrência cada vez mais acirrada eram os principais fatores contribuindo para a perda de clientes.
Diante desse cenário, a GadgetDotCom implementou uma nova iniciativa: a criação de uma área dedicada ao “Entendimento do Cliente”. O objetivo principal dessa área é fortalecer a estratégia de retenção e fidelização dos clientes. Para dar suporte a essa iniciativa, a empresa contratou um cientista de dados.
O cientista de dados propôs o desenvolvimento de um modelo de machine learning de alta precisão. Esse modelo será treinado com dados históricos dos clientes, como histórico de consumo, comportamento de navegação e feedback, para prever quais clientes estão mais propensos a cancelar seus serviços de streaming.
Com essa antecipação, a empresa poderá implementar ações personalizadas e proativas para reter esses clientes, como ofertas especiais de renovação, conteúdos exclusivos e recomendados com base no perfil do cliente, além de um atendimento personalizado para solucionar dúvidas e problemas. Essa abordagem permitirá não apenas reduzir a taxa de churn, mas também aumentar a satisfação dos clientes e fortalecer o relacionamento com a marca.
Mas afinal de contas, o que é o “Churn”?
Em Machine Learning, CHURN é a expressão que representa a previsão de um cliente deixar de utilizar um serviço ou produto de uma empresa:

Ou seja, churn é a taxa que mede a probabilidade de um cliente não mais realizar negócios com uma entidade.
Assim, as empresas passaram a utilizar modelos de Machine Learning para tentar identificar padrões de comportamento (predição) que possam indicar a probabilidade de um cliente se afastar da empresa, permitindo então, que as empresas desenvolvam estratégias (prescrição) para tentar reter tais clientes.
2 – Coleta de Dados
A pedido do Cientista de Dados, a GadgetDotCom extraiu um conjunto de dados do seu banco de dados e formatados em CSV. Nesse dataset, existem informações cruciais sobre os clientes, como: idade, volume de consumo mensal, tipo de plano contratado, nível de satisfação, duração do contrato, valor da mensalidade e, finalmente, se o cliente encerrou o contrato (churn).
Abaixo apresento alguns dados. Note que a última coluna será a representatividade do Churn, sendo que o “1” representará a efetivação do “churn” e o “0” será o “não churn”.
Idade,UsoMensal,Plano,SatisfacaoCliente,TempoContratual,ValorMensalidade,Churn 42,73,Basico,2,Curto,72.44,0 59,65,Premium,1,Curto,78.25,1 43,58,Standard,4,Longo,173.56,0 32,42,Basico,2,Longo,163.5,0 70,74,Standard,2,Longo,182.23,1 25,22,Standard,3,Medio,163.81,1 38,54,Basico,1,Medio,139.57,0 56,79,Basico,2,Medio,148.12,0 36,94,Basico,5,Longo,183.37,0 40,74,Premium,3,Curto,136.82,0 28,15,Standard,3,Longo,144.86,1 28,7,Premium,2,Medio,73.47,1 41,3,Premium,1,Medio,121.09,1 70,3,Basico,5,Longo,157.46,0 53,55,Premium,1,Longo,90.64,1 57,24,Basico,4,Medio,80.34,1 41,66,Standard,4,Medio,97.07,0 20,95,Basico,2,Medio,56.23,1 29,66,Premium,2,Longo,82.24,1 50,26,Premium,2,Medio,123.73,1
3 – Exploração dos dados
Para a criação e construção do modelo, será utilizado o google colab.
De início, realizar o import as bibliotecas que serão utilizadas no projeto.
#import de bibliotecas #manipulação dos dados import pandas as pd import numpy as np #visualização de dados e geração de gráficos import matplotlib.pyplot as plt import seaborn as sns #biblioteca para construção de modelos de machine learning import sklearn
Carregar os dados
Importadas as bibliotecas, realizo o carregamento dos dados
#carregando os dados
df_churn = pd.read_csv('/content/drive/MyDrive/dataset.csv')
Verifico algumas características dos dados como:
O tipo dos dados
#verificação do tipo de objeto type(df_churn)
pandas.core.frame.DataFrame
A dimensão dos dados. No caso, o dataset (conjunto de dados) possui 1000 registros (linhas) e 07 dimensões (colunas).
#dimensões da tabela df_churn.shape
(1000, 7)
Visualização das informações dos dados
#Info df_churn.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1000 entries, 0 to 999 Data columns (total 7 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Idade 1000 non-null int64 1 UsoMensal 1000 non-null int64 2 Plano 1000 non-null object 3 SatisfacaoCliente 1000 non-null int64 4 TempoContrato 1000 non-null object 5 ValorMensal 1000 non-null float64 6 Churn 1000 non-null int64 dtypes: float64(1), int64(4), object(2) memory usage: 54.8+ KB
Visualizar o Dataframe (objeto semelhante uma planilha de dados)
#visualização do dataframe df_churn.head()
Idade UsoMensal Plano SatisfacaoCliente TempoContrato ValorMensal Churn 0 56 52 Premium 1 Curto 75.48 0 1 69 65 Basico 4 Curto 79.25 0 2 46 76 Standard 3 Longo 183.56 0 3 32 42 Basico 2 Longo 162.50 0 4 60 74 Standard 2 Longo 186.23 1
Análise Exploratória dos Dados
Para a análise dos dados, utilizei as bibliotecas do matplotlib e seaborn para gerar os gráficos abaixo.
Para geração dos gráficos abaixo, utilizei o a função criada no post Automatizador para Análise Exploratória de Dados ![]() .
.
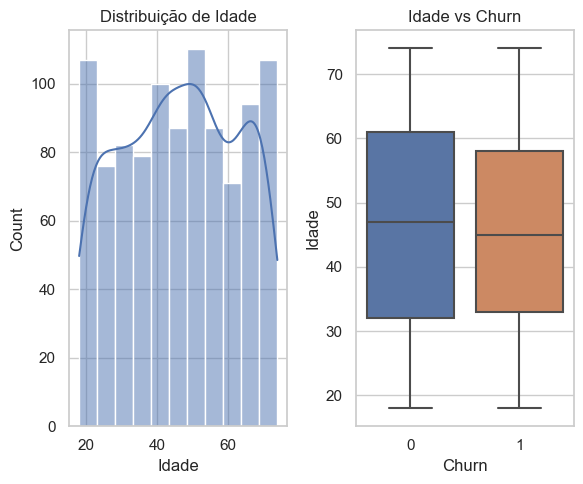
Pelo gráfico esquerdo, temos uma análise univariada (apenas uma variável) em que se verifica que algumas idades possuem uma maior frequência de usuários, como os clientes nas na faixa dos 20 anos, na casa dos 50 e 70 anos, enquanto outras são menores, porém não ocorre grandes discrepâncias. No gráfico mais a direita, temos uma análise bi-variada (duas variáveis), que são a “Idade” e o “Churn”. Nela podemos inferir, pela posição da medianas, que quem possui uma idade um pouco menor é mais propenso a cancelar o plano.
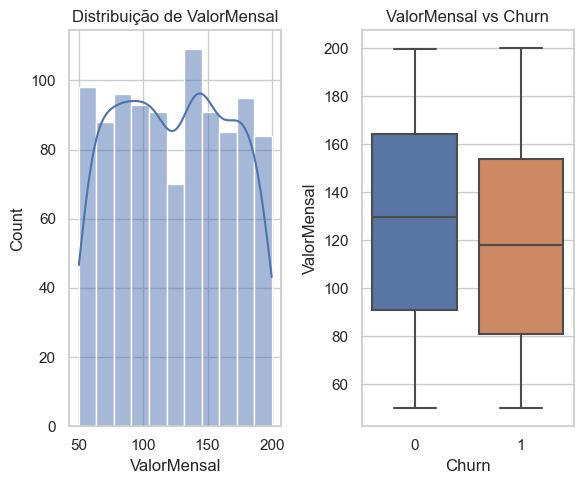
Para o ValorMensal do plano, há uma leve concentração nos planos entre R$ 130 e R$ 140, No boxplot podemos analisar que clientes com planos inferiores a R$ 120,00 tem mais probabilidade de realizar o churn.
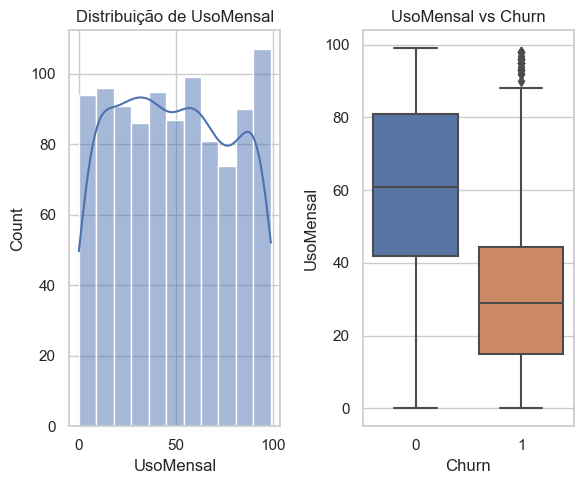
Quanto ao uso mensal, pode-se analisar os usuários com menor consumo estão mais propensos a cancelar. Faz sentido se pensarmos que, já que não conseguem utilizar, talvez por falta de tempo, manter o plano não se torna tão necessário. Nesta análise podemos observar a existência de outliers, pontos fora da curva, de alguns usuários que utilizam muito e mesmo assim cancelam os planos.
Divisão do Dataset em treino e teste
Após analisarmos os dados em profundidade, o próximo passo é dividi-los em conjuntos de treinamento e teste. Isso é fundamental para avaliar a performance de nossos modelos de machine learning. No post Automatizar a divisão de treino e teste em um dataset ![]() , mostrei como automatizar essa etapa usando Python, tornando o processo mais eficiente.
, mostrei como automatizar essa etapa usando Python, tornando o processo mais eficiente.
4 – Pré-processamento e limpeza de dados
O pré-processamento dos dados é uma etapa fundamental no desenvolvimento de modelos de Machine Learning. Ele consiste em transformar os dados brutos em um formato adequado para serem utilizados pelos algoritmos de aprendizagem de máquina. Essa preparação é crucial para garantir a eficiência dos modelos.
Outro detalhe que devemos nos atentar, é que o pré-processamento deve ser realizado após a divisão em conjuntos de treino e teste, conforme apresento no post Machine Learning: O Pré-processamento e o vazamento de informações ![]()
🤔 Mas por que mesmo que o pré-processamento é tão importante?
- Padronização dos dados: Os algoritmos de machine Learning funcionam melhor com dados numéricos e padronizados. O pré-processamento transforma, por exemplo, dados categóricos em numéricos, facilitando o aprendizado do modelo.
- Remoção de ruídos: Dados reais podem conter ruídos, outliers ou valores faltantes. O pré-processamento ajuda a identificar e tratar esses problemas, melhorando a qualidade dos dados.
- Geração de features: O pré-processamento pode envolver a criação de novas features a partir dos dados existente. Tal procedimento pode melhorar a capacidade do modelo em capturar padrões complexos.
Técnicas Comuns de Pré-processamento
Existem diversas técnicas de pré-processamento, cada uma com suas particularidades e aplicações. As duas técnicas mais utilizadas são o one-hot encoding e o standard scaler.
- One-hot encoding: Essa técnica transforma variáveis categóricas (ex: sim ou não) em um formato numérico que os algoritmos de machine learning possam entender. Ela consiste em criar novas colunas binárias para cada categoria, onde o valor 1 (um) indica a presença daquela categoria e o valor 0 (zero) indica a ausência. Exemplo: a variável “cor” com as categorias “vermelho”, “azul” e “verde” seria transformada em três novas colunas: “cor_vermelho”, “cor_azul” e “cor_verde”.
- Standard scaler: Essa técnica é utilizada para padronizar as variáveis numéricas, transformando-as em escala comum.
Quando usar cada técnica?
- One-hot encoding: Deve ser aplicado a variáveis categóricas nominais, ou seja, aquelas que não possuem uma ordem natural entre as categorias.
- Standard scaler: Deve ser aplicado em variáveis numéricas contínuas, como idade, peso, altura, etc.
One_hot encoding
Primeiramente deve ser criado um dataframe apenas com as “colunas categóricas”.
#Aplicando One-hot encoding aos conjuntos de treino e teste encoder = OneHotEncoder(sparse_output = False) #Treinando o enconder com o conjunto de treino e transformando X_train_encoded = pd.DataFrame(encoder.fit_transform(X_train[colunas_categoricas])) #Transformando e teste X_test_encoded = pd.DataFrame(encoder.transform(X_test[colunas_categoricas]))
Standard Scaler
A exemplo do One-hot encoding, criar um dataframe apenas com colunas numéricas.
#Criando o StandarSclaer scaler = StandardScaler() #aplicando o StandardScaler as variaveis numericas nos dados de treino X_train_preprocessed[numerical_colunas] = scaler.fit_transform(X_train_preprocessed[numerical_colunas]) X_test_preprocessed[numerical_colunas] = scaler.transform(X_test_preprocessed[numerical_colunas])
5 – Modelagem
Como já anunciado no título do post, o modelo de machine learning que foi utilizado para predição do churn foi o Random Forest.
O Random Forest é uma algoritmo poderoso e versátil de machine learning que combina a simplicidade das árvores de decisão com a complexidade de uma floresta. Pela sua capacidade de lidar com grandes conjuntos de dados, alta dimensionalidade e ruído, além de sua precisão, o tornaram uma ferramenta muito popular em diversas áreas de negócio, como finanças, medicina, marketing e engenharia.

Em resumo, Random Forest é como fazer uma pesquisa com diversos especialistas. Cada especialista (árvore) dá sua opinião, e a opinião mais popular é a resposta final. Essa abordagem democrática e diversificada leva a resultados mais confiáveis e robustos
Assim, iniciamos o modelo e executamos.
#Criando o modelo random forest modelo_churn = RandomForestClassifier(random_state = 42) #valor padrão #treinando o modelo modelo_churn.fit(X_train_preprocessed, y_train) #Fazendo a previsão com os dados de teste y_pred = modelo_churn.predict(X_test_preprocessed)
Visualização das métricas
#Avaliando o modelo acuracia = accuracy_score(y_test, y_pred) relatorio_classificacao = classification_report(y_test, y_pred)
Verificamos a acurácia
acuracia
0.7966666666666666
O modelo retornou uma acurácia de 79,66%, praticamente 80%.
Abaixo temos as demais métricas, como a precisão, recall e o f1-score.
print(relatorio_classificacao)
precision recall f1-score support
0 0.83 0.84 0.83 182
1 0.74 0.74 0.74 118
accuracy 0.80 300
macro avg 0.79 0.79 0.79 300
weighted avg 0.80 0.80 0.80 300
6 – Avaliação e melhoria do modelo
Validação Cruzada
A validação cruzada é uma técnica fundamental em machine learning, servindo para avaliar a performance do modelo e evitar o overfiting. Ela consiste em dividir o conjunto de dados em diversos subconjuntos, chamados de folds. Cada fold é utilizado, por sua vez, como conjunto de teste, enquanto os demais são usados para treinar o modelo.
Por que usar a Validação Cruzada?
- Estimação mais precisa do erro: Ao avaliar o modelo em diferentes subconjuntos de dados, obtém-se uma estimativa mais robusta do erro de generalização, ou seja, como o modelo se comporta em dados nunca antes vistos;
- Prevenção de overfiting: O overfiting ocorre quando o modelo se ajusta demais aos dados de treino, perdendo a capacidade de generalizar para dados novos. A validação cruzada ajuda a mitigar esse problema;
- Otimização de hiperparâmetros: A validação cruzada é utilizada para encontrar os melhores valores para os hiperparâmetros de um modelo, como a taxa de aprendizado em redes neurais ou a profundidade de uma árvores de decisão;
- Comparação de modelos: Permite comparar diferentes algoritmos e hiperparâmetros de forma mais justa, escolhendo o modelo que apresenta o melhor desempenho de forma generalizada.
# Modelo RandomForest com validação cruzada modelo_churn_VC = RandomForestClassifier(random_state = 42) # Realizando a validação cruzada # Usaremos 5 folds para a validação cruzada cv_scores = cross_val_score(modelo_cv, X_train_preprocessed, y_train, cv = 5)
vc_scores
array([0.75714286, 0.76428571, 0.75 , 0.71428571, 0.70714286])
Otimização dos Hiperparâmetros
A otimização de hiperparâmetros é uma etapa crucial no desenvolvimento de modelos de machine learning. Ao ajustar os hiperparâmetros de um modelo, pode-se:
- Melhorar o desempenho: Hiperparâmetros bem ajustados podem levar a modelos mais precisos, capazes de fazer previsões mais acuradas;
- Reduzir o Overfiting e Underfiting: A otimização pode ajudar a encontrar um ponto ideal entre a complexidade do modelo e sua capacidade de generalizar para novos dados;
- Aumentar a eficiência: Modelos com hiperparâmetros otimizados tendem a convergir mais rapidamente para uma solução ótima, economizando tempo de treinamento;
- Reprodutibilidade: A documentação do processo de otimização dos hiperparâmetros garantem a reprodutibilidade dos resultados para as aplicações práticas;
Existem algumas técnicas de otimização, como:
- Grid Search: Uma abordagem que testa todas as combinações possíveis de valores para os hiperparâmetros;
- Random Search: Uma abordagem mais eficiente que amostra aleatoriamente diferentes combinações de valores;
- Bayesian Optimization: Uma abordagem que utiliza modelos probabilísticos para encontrar a melhor combinação de hiperparâmetros;
- Gradient-based Optimization: Técnica que utiliza o cálculo de gradientes para encontrar a direção de otimização.
Agora vamos configurar os hiperparâmetros
#Definindos os hiperparâmetros
param_gridS = {
'n_estimators': [50, 100, 200], #numero de árvores
'max_depth': [None, 10, 20, 30], #profundidade máxima da árvore
'min_samples_split': [2, 4, 6], #número mínimo de amostras para dividir um nó
'min_samples_leaf': [1, 2, 4] #número mínimo de amostras exigidas em cada folha
}
#Criar modelo otimizado modelo_otimizado = RandomForestClassifier(random_state = 42) #Configuração da busca em grade com validadção cruzada grid_search = GridSearchCV(modelo_otimizado, param_gridS, cv =5, scoring = 'accuracy', n_jobs = -1)
E realiza-se a otimização com o conjunto de dados de treino.
grid_search.fit(X_train_preprocessed, y_train)
Configura o retorno dos melhores parâmetros e resultados (levou-se em consideração a acurácia).
#Melhores parâmetros best_params = grid_search.best_params_ best_score = grid_search.best_score_
Executando…
best_params, best_score
Temos os possíveis melhores parâmetros
({'max_depth': 10,
'min_samples_leaf': 1,
'min_samples_split': 2,
'n_estimators': 50},
0.7528571428571429)
Agora vamos trabalhar na versão final do modelo.
Versão Final do Modelo
Chegou o momento de executarmos o modelo com os melhores hiperparâmetros escolhidos.
# melhores hiperparâmetros
dfChurn_final = RandomForestClassifier(n_estimators = best_params['n_estimators'],
max_depth = best_params['max_depth'],
min_samples_split = best_params['min_samples_split'],
min_samples_leaf = best_params['min_samples_leaf'],
random_state = 42)
Executamos o fit do modelo.
# Treinando o modelo final com o conjunto de treino dfChurn_final.fit(X_train_preprocessed, y_train)
Salvando os valores previstos
# Previsões com dados de teste y_pred_final = dfChurn_final.predict(X_test_preprocessed)
# Avaliando o modelo final no conjunto de teste final_accuracy = accuracy_score(y_test, y_pred_final) final_classification_report = classification_report(y_test, y_pred_final)
final_accuracy
Como resultado, temos: 0.8 – 80%
Gerando o relatório final.
print(final_classification_report)
precision recall f1-score support
0 0.85 0.82 0.83 182
1 0.73 0.77 0.75 118
accuracy 0.80 300
macro avg 0.79 0.79 0.79 300
weighted avg 0.80 0.80 0.80 300
Deploy
Para o deploy foi escolhida a plataforma streamlit, que é uma biblioteca python de código aberto para construção de aplicativos web.
Abaixo temos a aplicação em funcionamento.