
Período de 2017 a 2020
São Luís, comumente referida como São Luís do Maranhão, destaca-se como a capital do estado do Maranhão, com uma história rica e peculiar.
Fundada em 8 de setembro de 1612 pelos franceses, a cidade foi palco de diversas invasões, incluindo a dos holandeses, antes de ser finalmente colonizada pelos portugueses. Essa trajetória multifacetada deixou marcas na sua cultura e arquitetura.
Em 1997, a UNESCO reconheceu o valor do centro histórico de São Luís ao declará-lo Patrimônio Cultural da Humanidade, um testemunho da importância histórica e cultural da região.
Geograficamente situada na ilha de Upaon-Açu, no Atlântico Sul, São Luís é delimitada pelas baías de São Marcos e São José de Ribamar, inserida no contexto do Golfão Maranhense. Vale ressaltar que Upaon-Açu não abriga apenas São Luís, mas também os municípios de São José de Ribamar, Paço do Lumiar e Raposa, formando o que é conhecido como Grande Ilha.


Para uma análise completa, é imprescindível considerar dados de todos os municípios que compõem essa região, uma vez que cada um contribui de forma única para a dinâmica socioeconômica e demográfica da Grande Ilha.
MVI
A metodologia MVI (Mortes Violentas Intencionais) é a metodologia utilizada pelo Instituto de Pesquisas Econômicas Aplicada (IPEA) e pelo Fórum Brasileiro de Segurança Pública (FSBP) para a elaboração dos “Atlas da Violência”. Os MVIs contemplam, como forma de mortalidade violenta, os homicídios dolosos, latrocínios (roubos seguidos de morte), lesões corporais seguida de morte, vitimização policial, mortes decorrentes de intervenção policial, lesões com morte posterior, mortes em estabelecimentos prisionais e mortes a esclarecer com indícios de crime violento.
DATASET – CONJUNTO DE DADOS
Os dados utilizados são as ocorrências de MVI para o município de São Luís monitorados pelo Centro de Apoio Operacional Criminal, do Ministério Público do Estado do Maranhão, do período de 2017 a até o mês de maio de 2020.
Abaixo temos a definição do caminho do dataset e a transformação do arquivo em DataFrame.
DataFrame– É uma estrutura bidimensional (semelhante a uma planilha) que traz agilidade na manipulação dos dados. O DataFrame é composo por Series, que são estruturas unidimensionais que suportam variados tipos de dados (string, interger, float, datetime).
#
#importação de bibliotecas necessárias
import pandas as pd
df_vslz = pd.read_csv('/content/drive/My Drive/Colab Notebooks/dataset/dataset.csv')
#
Criado o DataFrame df_vslz (que seria uma abreavição criada a partir do texto “DataFrame da Violência da Grande Ilha de São Luís”), realizamos o carregamento dos dados e visualizado os 05 primeiros registros do dataset.
# #visualização das 05 primeiras entradas df_vslz.head() #
ID Data Sexo Idade Horário CAUSA DA MORTE Local Município Classificação 0 1 01/01/2017 masculino 22.0 03:01:00 ARMA BRANCA Coroadinho São Luís HOMICÍDIO DOLOSO 1 2 01/01/2017 masculino 30.0 00:21:00 ARMA DE FOGO Liberdade São Luís HOMICÍDIO DOLOSO 2 3 01/01/2017 masculino 23.0 18:30:00 ARMA DE FOGO São Raimundo São Luís HOMICÍDIO DOLOSO 3 4 01/01/2017 masculino 38.0 20:21:00 ARMA DE FOGO Vila Conceição – Coroadinho São Luís HOMICÍDIO DOLOSO 4 5 01/01/2017 feminino 49.0 23:22:00 ARMA DE FOGO Vila Vitória São Luís HOMICÍDIO DOLOSO
Quantidade de registros
DataFrame df_vslz criado e visualizado. Agora vamos verificar algumas informações básicas dele, como a quantidade de registros (linhas, rows) e as Series (colunas).
#
#Verificar a quantidade de linhas e colunas
print('Quantidade de linhas: {}'.format(df_vslz.shape[0]))
print('Quantidade de colunas: {}'.format(df_vslz.shape[1]))
#
Quantidade de linhas: 1536 Quantidade de colunas: 9
Tipos de dados
Após a criação e visualização do DataFrame, procedemos à verificação da quantidade de registros. Agora, é fundamental analisar os tipos de dados que compõem nosso conjunto de dados. Esse processo de verificação é conduzido pelo código abaixo:
# #tipos dos dados das colunas df_vslz.dtypes #
ID int64 Data object Sexo object Idade float64 Horário object CAUSA DA MORTE object Local object Município object Classificação object dtype: object
Verifica-se que os campos Data, e Horário estão com tipos de dados inadequados.
Data– Apresenta tipostring(texto) quando deveria ser do tipodatetime(formato adequado para datas e horários;Horário– Apresenta tipostring(texto) quando deveria ser do tipodatetime(formato adequado para datas e horários;
Transformação – Adequação de tipos de dados indevidos
Após a verificação de tipos de dados inadequados, o acerto se da a partir dos procedimentos abaixo:
# #modificação dos tipos de dados #acerto da coluna Data para o tipo de dado 'datetime' df_vslz['Data'] = pd.to_datetime(df_vslz['Data'], format= '%d/%m/%Y') #acerto da coluna Horário para o tipo de dado 'datetime' df_vslz['Horário'] = pd.to_datetime(df_vslz['Horário'], format='%H:%M:%S') #
Efetuada a alteração, executamos o código novamente para verificação
# df_vslz.dtypes #
ID int64 Data datetime64[ns] Sexo object Idade float64 Horário datetime64[ns] CAUSA DA MORTE object Local object Município object Classificação object dtype: object
Dicionário de dados
Ao trabalhar com datasets é normal recorrermos a uma tabela organizada, onde podemos encontrar as especificações dos elementos, os tipos de dados, as correspondências e descrições de códigos (ex: 1 se refere a federal, 2 a estadual, etc.).
A esta coleção de metadados que contém definições e representações de elementos de dados damos o nome de Dicionário de Dados.
Abaixo vamos criar um dicionário simplificado.
Primeiramente, vamos obter uma lista com os nomes das Series ou colunas.
# #retorna uma lista com os nomes das colunas df_vslz.columns #
Index(['ID', 'Data', 'Sexo', 'Idade', 'Horário', 'CAUSA DA MORTE', 'Local',
'Município', 'Classificação'],
dtype='object')
No DataFrame a coluna CAUSA DA MORTE está em uppercase, vamos aproveitar e alterá-la para Causa_morte.
#
#remomear coluna
df_vslz.rename(columns={'CAUSA DA MORTE': 'Causa_morte'}, inplace=True)
#visualizar os nomes das colunas com as modificações
df_vslz.columns
#
Index(['ID', 'Data', 'Sexo', 'Idade', 'Horário', 'Causa_morte', 'Local',
'Município', 'Classificação'],
dtype='object')
Montando o dicionário
-Data (datetime)- Data da ocorrência do fato; -Sexo (string)- Gênero da vítima; -Idade(float) - Idade da vítima; -Horário (datetime)- Horário da ocorrência do fato; -Causa_morte (string) - Especificação da causa ou do instrumento utilizado; -ARMA DE FOGO; -ARMA BRANCA; -ESPANCAMENTO; -ESTRANGULAMENTO; -OUTROS MEIOS; -Local (string)- Bairro ou localidade da ocorrência; -Município (string)- Município da Grande Ilha de São Luís; -Classificação(string) - Classificação da ocorrência -HOMICÍDIO DOLOSO; -LESÃO C S MORTE - LESÃO CORPORAL SEGUIDA DE MORTE; -LATROCÍNIO; -MORTE D I POLICIAL - MORTE DECORRENTE DE INTERVENÇÃO POLICIAL; -MORTE ESCLARECER - MORTE A ESCLARECER (COM INDÍCIOS DE MVI); -MORTE POSTERIOR (COM INDÍCIOS DE MVI)
Valores ausentes
Valores ausentes possuem uma enorme influencia na criação de modelos, provocando distorções nas análises. Por vezes, temos que decidir se os registros (linhas) devem ser excluídos ou preenchidos por algum valor.
Como abordagem para contornar o problema, podemos padronizar uma definição de “valor ausente” ou preenchê-lo com algum parâmetro estatístico, podendo escolher a moda, mediana, média do conjunto de dados.
No caso dos dados em estudo, optamos por preencher o valor faltante por UNKNOWN (desconhecido), preservando assim todos os registros.
Abaixo, estabelecemos a rotina para verificarmos o quantitativo de valores ausentes e o percentual desses valores frente ao total de registros.
Quantitativo
#
#verificação dos valores ausentes
for i in df_vslz.columns:
print('Valores ausentes em ' + i +':{}'.format(df_vslz[i].isnull().sum()))
#
Valores ausentes em ID: 0 Valores ausentes em Data: 0 Valores ausentes em Sexo: 3 Valores ausentes em Idade: 14 Valores ausentes em Horário: 25 Valores ausentes em Causa_morte: 1 Valores ausentes em Local: 7 Valores ausentes em Município: 7 Valores ausentes em Classificação: 0
Percentual
#
#porcentagem de valores ausentes
#porcentagem = df_vslz[i].isnull().sum()/ df_vslz.shape[0]
for i in df_vslz.columns:
print('Valores ausentes em ' + i + ': {:,.2f}% '.format(df_vslz[i].isnull().sum()/ df_vslz.shape[0] * 100))
#
Valores ausentes em ID: 0.00% Valores ausentes em Data: 0.00% Valores ausentes em Sexo: 0.20% Valores ausentes em Idade: 0.91% Valores ausentes em Horário: 1.63% Valores ausentes em Causa_morte: 0.07% Valores ausentes em Local: 0.46% Valores ausentes em Município: 0.46% Valores ausentes em Classificação: 0.00%
Verificamos que a dimensão/coluna com maior percentual de valores ausentes é o campo Horário.
Preenchimento dos valores faltantes.
#
#preenchimento dos valores ausentes
df_vslz.fillna('UNKNOWN', axis=1, inplace=True)
#
Validação da rotina anterior.
# #Vericiação dos valores ausentes df_vslz.isnull().sum() #
ID 0 Data 0 Sexo 0 Idade 0 Horário 0 Causa_morte 0 Local 0 Município 0 Classificação 0 dtype: int64
Pronto! Todos os item estão preenchidos.
Correlação
Na análise desta seção, verificaremos a correlação entre as colunas.
A correlação mede a relação de dependência entre as variáveis, sendo extremamente útil para modelos de ML – Machine Learning (Aprendizagem de máquina).
# #para tal importaremos a biblioteca seaborn import seaborn as sns import matplotlib.pyplot as plt #%matplotlib notebook fig, ax = plt.subplots() sns.heatmap(df_vslz.corr()) plt.show() #

Verificamos que o algoritimo encontrou apenas a variavel ID, por entender que apresenta valores numéricos.
Podemos optar em realizar um mapeamento das variáveis Sexo, Município, Causa_morte e Classificação quando formos trabalhar com modelos de ML, utilizando técnicas de codificação. No Projeto 01 – Modelo de Machine Learning para área de logística – deploy em Flask realizo uma rotina de codificação, com técnicas de encoder, para as variáveis “tipo da embalagem” e “tipo do produto”.
AGRUPAMENTOS
Nesta seção vamos extrair alguns insights dos dados, a partir da criação de gráficos “no braço” utilizando a biblioteca seaborn.
Totais
Aqui vamos buscar os totais de ocorrências por municípios.
# #Agrupamento de valores por município df_vslz.groupby(['Município'])['ID'].count() #
Município Paço do Lumiar 108 Raposa 22 São José de Ribamar 228 São Luís 1171 UNKNOWN 7 Name: ID, dtype: int64
Abaixo temos uma rotina para adequar o rótulo à grade do gráfico.
# #Filtrar o valor máximo para usálo nos limites da imagem df_vslz.groupby(['Município'])['ID'].count().max() #atribuí-lo para variável ymaximo ymaximo_g01 = df_vslz.groupby(['Município'])['ID'].count().max() #
Foi criado novamente a rotina para o gráfico 02
# #atribuí-lo para variável ymaximo ymaximo_g02 = df_vslz.groupby(['Causa_morte'])['ID'].count().max() #
Gráficos
Agora vamos criar nossos primeiros gráficos, filtrando as ocorrências por municípios e causa da morte / instrumento utilizado.
#
import seaborn as sns
sns.set(style="white")
fig, (ax1, ax2) = plt.subplots(nrows=2, ncols=1,figsize=(17,8))
sns.countplot(df_vslz['Município'], palette='Blues_r', ax=ax1)
ax1.set_title('Quantitativos de 2017 a 2020')
ax1.set_xlabel('Município')
ax1.set_ylabel('Quantidade')
#instrução para que o rótulo não sobreponha a grade que circunda o gráfico
ax1.set_ylim(0, ymaximo_g01 + 100)
#GRÁFICO 01
for p in ax1.patches:
#Não tulizaremos valores decimais nos rótulos
#ax1.annotate("%.2f" % p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()),
ax1.annotate(p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', fontsize=13, color='black', xytext=(0, 10),
textcoords='offset points')
#To make space for the annotations
#GRÁFICO 02
sns.countplot(df_vslz['Causa_morte'], palette='Blues_d', ax=ax2)
ax2.set_xlabel('Causa da morte')
ax2.set_ylabel('Quantidade')
ax2.set_ylim(0, ymaximo_g02 + 100)
#laço para inclusão dos rótulos
for p in ax2.patches:
#Não tulizaremos valores decimais nos rótulos
#ax1.annotate("%.2f" % p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()),
ax2.annotate(p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', fontsize=13, color='black', xytext=(0, 10),
textcoords='offset points')
fig.show()
#fig.autofmt_xdate()
fig.tight_layout()
plt.show()
#
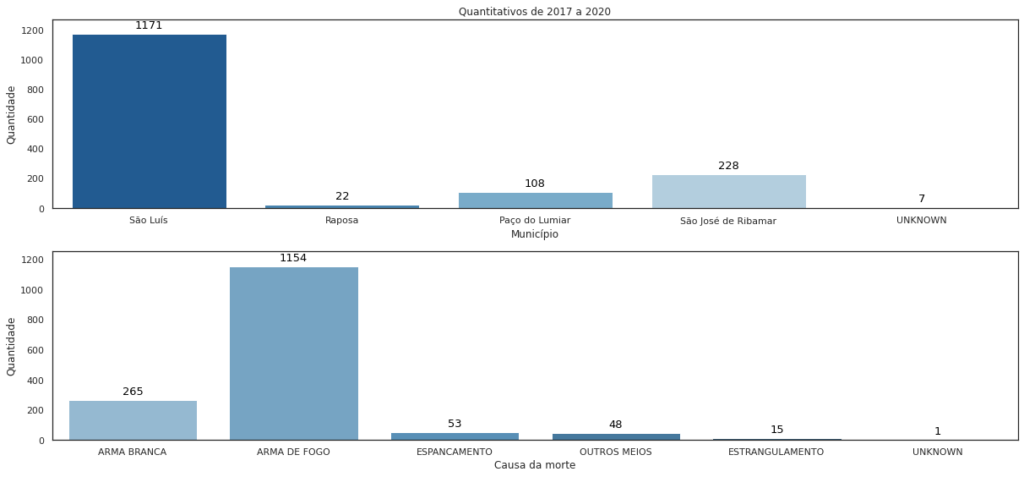
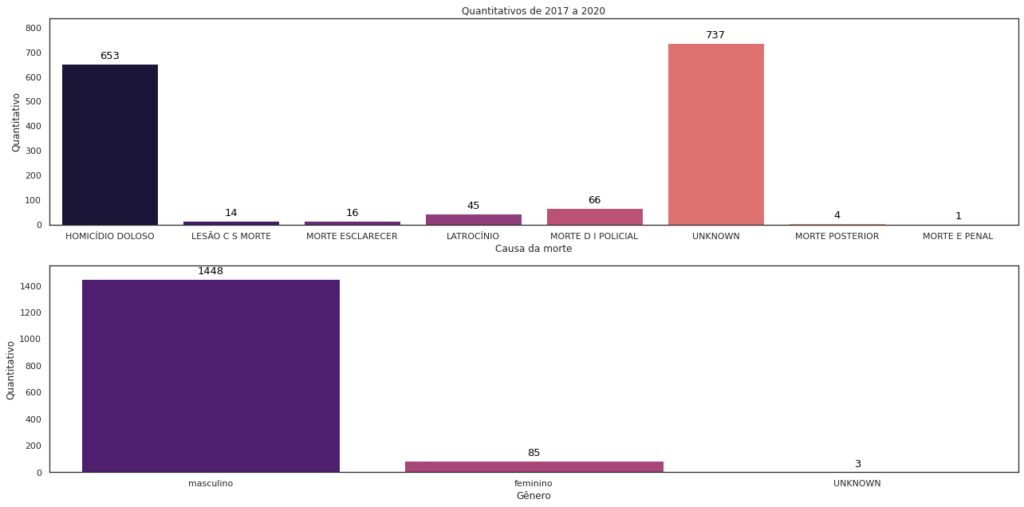
Nos gráficos abaixo, temos o agrupamento por classificação da ocorrência e pelo gênero da vítima.
#
ymaximo_g03 = df_vslz.groupby(['Classificação'])['ID'].count().max()
ymaximo_g04 = df_vslz.groupby(['Sexo'])['ID'].count().max()
sns.set(style="white")
fig, axe = plt.subplots(2,1, figsize=(18,9))
#GRÁFICO 03
#sns.countplot(df_vslz['Classificação'], palette='magma', ax=axe[0,0])
sns.countplot(df_vslz['Classificação'], palette='magma', ax=axe[0])
axe[0].set_title('Quantitativos de 2017 a 2020')
axe[0].set_ylabel('Quantitativo')
axe[0].set_xlabel('Causa da morte')
axe[0].set_ylim(0, ymaximo_g03 + 100)
for p in axe[0].patches:
#Não tulizaremos valores decimais nos rótulos
#ax1.annotate("%.2f" % p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()),
axe[0].annotate(p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', fontsize=13, color='black', xytext=(0, 10),
textcoords='offset points')
#GRÁFICO 04
sns.countplot(df_vslz['Sexo'], palette='magma', ax=axe[1])
axe[1].set_ylabel('Quantitativo')
axe[1].set_xlabel('Gênero')
axe[1].set_ylim(0, ymaximo_g04 + 100)
for p in axe[1].patches:
#Não tulizaremos valores decimais nos rótulos
#ax1.annotate("%.2f" % p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()),
axe[1].annotate(p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', fontsize=13, color='black', xytext=(0, 10),
textcoords='offset points')
fig.show()
#
fig.tight_layout()
#
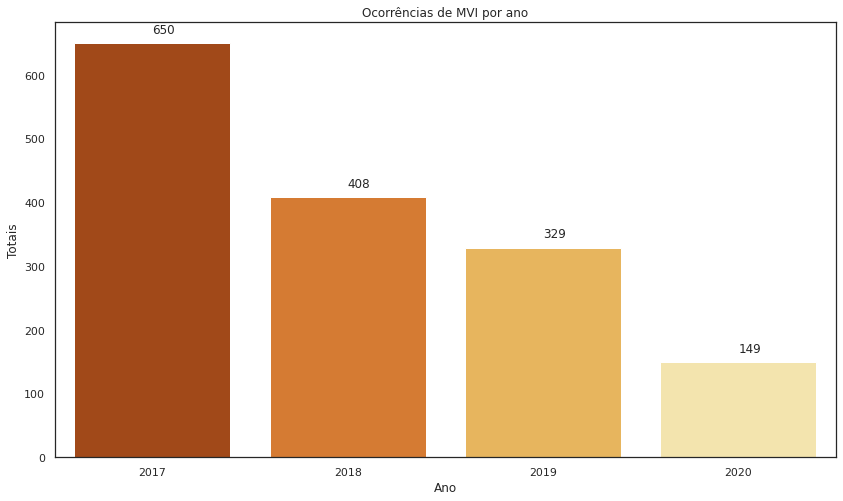
Na próxima visualização, agruparemos o quantitativo das ocorrências por ano.
# #realizar a contagem df_vslz['Data'].dt.year.value_counts() #
2017 650 2018 408 2019 329 2020 149 Name: Data, dtype: int64
Gerar o gráfico para o filtro acima.
#
x = df_vslz['Data'].dt.year
sns.set(style='white')
fig, ax = plt.subplots(figsize = (14,8))
sns.countplot(x, palette='YlOrBr_r', ax=ax)
ax.set_title('Ocorrências de MVI por ano')
ax.set_xlabel('Ano')
ax.set_ylabel('Totais')
for p in ax.patches:
ax.annotate(p.get_height(), (p.get_x() + p.get_width() / 2., p.get_height()),
xytext=(0,10), textcoords='offset points' )
#fig.autofmt_xdate()
plt.show()
fig.tight_layout
#
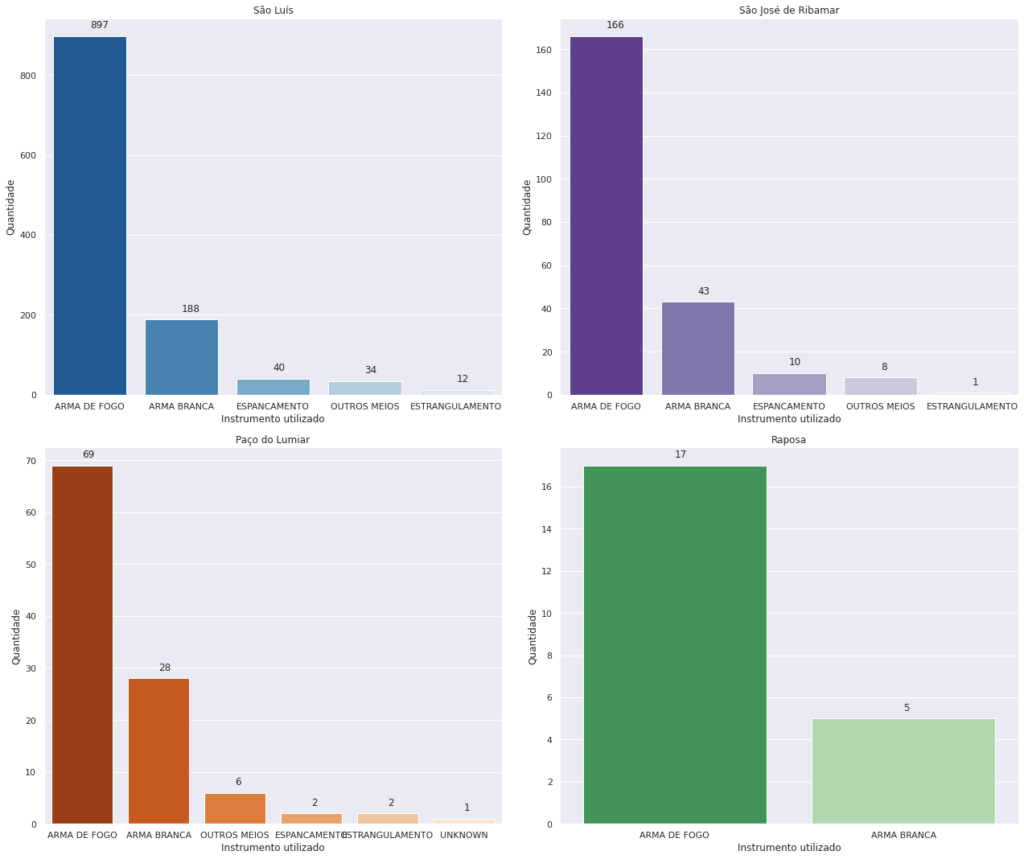
Com base nos códigos acima, outros recortes e gráficos foram construídos e apresentados logo abaixo.
Instrumento utilizado na morte violenta, por município da Grande Ilha, no período de estudo/análise.
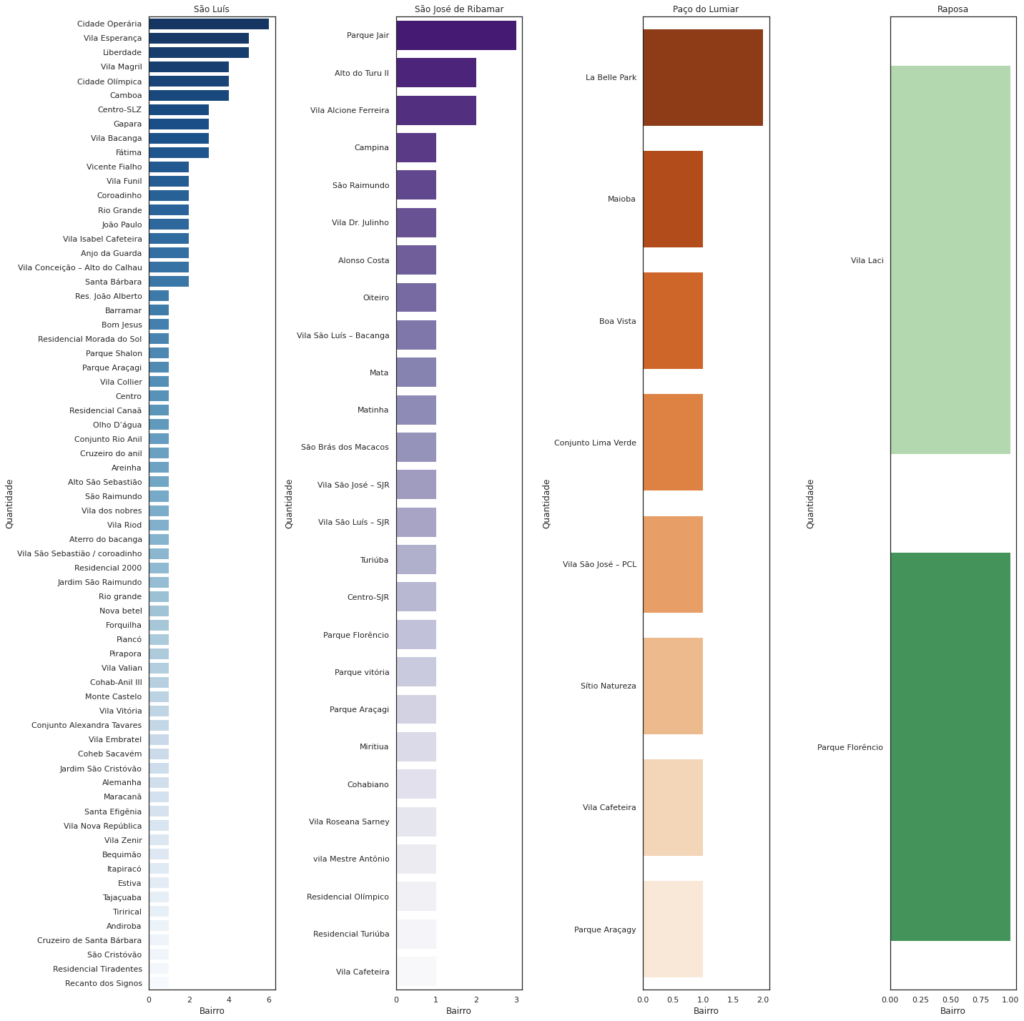
Filtro de bairro com maior número de ocorrências de morte violenta, por município, no período de estudo/análise.
CONCLUSÃO
Ao trabalhar com o dataset podemos percerber que ainda existem dados a serem tratados ( e isso representa praticamento 80% de todo um projeto de data science), como os valores ausentes.
Pudemos retirar insights valorosos, como aferir que:
- As armas de fogos são os instrumentos que mais causam mortes, seguidos pelas armas brancas. Mas também notamos que os espancamentos possuem uma quantidade expressiva de ocorrências.
- São Luís possui a maior quantidade de ocorrências (possui a maior população), enquanto Raposa possui as menores quantidades (município com menor população).
- Verificamos que o bairro Cidade Operária é o bairro mais violento de São Luís, considerando os registros de 2020 até o mês de maio.
Outros insights podem ser tirados dos dados, bastando escolhermos o contexto.
Tenham uma proveitosa leitura e grande abraço!
Uma resposta para “Projeto 03 – Análise Exploratória de Dados – Mortalidade Violenta na Grande Ilha de São Luís”
[…] Projeto 03 – Análise Exploratória de Dados – Mortalidade Violenta na Grande Ilha de São Luís, partimos de uma base de dados e analisamos o conjunto de dados em si, empregando a linguagem […]