
O que é o mecanismo de atenção das redes transformers?
As LLMs
No post “As LLMs no nosso mundo“, discutimos detalhadamente as vantagens e desvantagens dos Modelos de Linguagem de Grande Escala (LLMs, na sigla em inglês). Estes modelos, que utilizam técnicas avançadas de aprendizado de máquina para processar e gerar linguagem natural, têm revolucionado diversas áreas, desde a automação de atendimento ao cliente até a criação de conteúdo.
Entre as principais vantagens, destacam-se a capacidade de compreender e responder a uma vasta gama de perguntas, a eficiência na análise de grandes volumes de texto e a versatilidade em adaptar-se a diferentes contextos e idiomas. Além disso, os LLMs têm se mostrado úteis na personalização de experiências de usuário, proporcionando respostas mais precisas e relevantes com base em interações anteriores.
Por outro lado, existem desvantagens significativas. A necessidade de grandes quantidades de dados para treinamento levanta questões sobre privacidade e segurança. Os custos computacionais elevados e o consumo de energia são preocupações adicionais. Além disso, os LLMs podem reproduzir vieses presentes nos dados de treinamento, levando a respostas inadequadas ou discriminatórias.
Mas como são feitas as LLMs?
As LLMs (Modelos de Linguagem de Grande Escala) são desenvolvidas com base em uma arquitetura inovadora conhecida como modelo Transformer.
Mas o que é um modelo Trasnformer?
Uma rede Transformer é uma arquitetura de rede neural
Ela foi introduzida em 2017 pelo artigo “Attention is All You Need“, revolucionando o campo do processamento de linguagem natural (PLN) e outras tarefas sequenciais. Diferente das redes neurais recorrentes (RNNs), que processam dados sequencialmente.
O Transformer usa mecanismos de atenção para processar toda a sequência de dados simultaneamente.
Além disso, a estrutura do Transformer é composta por blocos de codificadores (encoders) e decodificadores (decoders). Os codificadores processam a entrada (input) e geram representações abstratas, enquanto os decodificadores usam essas representações para produzir a saída.
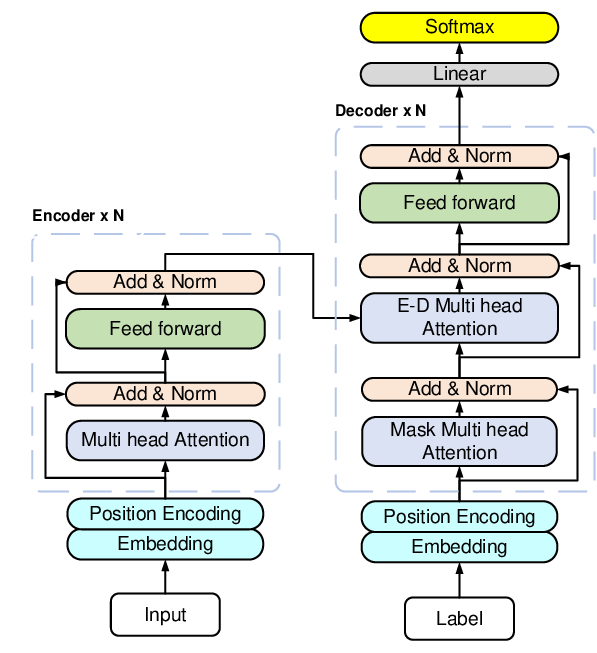
Essa abordagem permite maior paralelismo no processamento de dados, resultando em treinamento mais rápido e melhor desempenho em tarefas complexas, como tradução automática, geração de texto e compreensão de linguagem. Modelos como BERT e GPT, que são baseados em Transformadores, têm demonstrado resultados notáveis em diversas aplicações de PLN.
Tentando explicar o mecanismo de ATENÇÃO!
A principal inovação do modelo/arquitetura transformer é a “atenção”. É ela quem permite que a rede avalie a importância de diferentes partes da sequência de entrada em relação a cada posição de saída. Isso é feito através dos chamados mecanismos de autoatenção, onde cada palavra ou token na entrada pode “prestar atenção” a todas as outras palavras da sequência, ponderando-as de acordo com a relevância.
Aqui temos uma exemplificação de como o mecanismo de atenção funciona:
– Ela derramou água da jarra para o copo até que ficasse cheio.
- Sabemos que “cheio” se refere ao copo, enquanto na frase:
– Ela derramou água da jarra para o copo até que ficasse vazia.
- Sabemos que “vazia” se refere à jarra.
Em vez de processar a entrada de maneira sequencial, como fazem as redes neurais recorrentes (RNNs), o mecanismo de atenção permite que o modelo considere todas as partes da entrada simultaneamente.
Isso é realizado calculando pesos de atenção que determinam a importância de cada palavra em relação às outras.
Aqui está uma explicação mais detalhada do processo:
- Vetores de Consulta, Chave e Valor: Para cada palavra na sequência, o Transformer gera três vetores: uma consulta (query – Q), uma chave (key – K) e um valor (value – V). Esses vetores são criados a partir de multiplicações matriciais com os pesos aprendidos durante o treinamento.
- Pontuações de Atenção: As consultas são comparadas com todas as chaves para calcular as pontuações de atenção. Isso é feito através de um produto escalar seguido por uma normalização com a função softmax, que transforma essas pontuações em probabilidades.
- Pesagem e Soma: As pontuações de atenção são usadas para ponderar os valores correspondentes. Cada valor é multiplicado pela sua pontuação de atenção, e os resultados ponderados são somados, gerando um vetor de atenção para cada palavra.
- Mecanismo de Multi-cabeça: Para capturar diferentes aspectos da relação entre palavras, o Transformer usa várias “cabeças de atenção” paralelas. Cada cabeça opera de forma independente, e seus resultados são concatenados e projetados de volta para o espaço original.
Para o próximo projeto, me proponho a implementar o mecanismo de atenção, em python. A fim de proporcionar um entendimento mais completo.
Grande abraço a todos!
Uma resposta para “O “mecanismo de atenção” em uma IA generativa”
[…] post, será uma complementação prática do post “O mecanismo de atenção em uma IA Generativa“, em que foi explanado, em linhas gerais, o que é o mecanismo de atenção de uma […]